
# Árboles de Análisis Abstracto
Un Árbol de Análisis Abstracto (denotado AAA, en inglés AST) porta la misma información que el árbol de análisis sintáctico concreto (denominado también parsing tree) pero de forma mas condensada, eliminándose terminales y producciones que no aportan información.
The data structure that the parser will use to describe a program consists of node objects, each of which has a type property indicating the kind of expression it is and other properties to describe its content.
El árbol de análisis sintáctico abstracto es una representación compacta del árbol de análisis sintáctico concreto que contiene la misma información que éste.
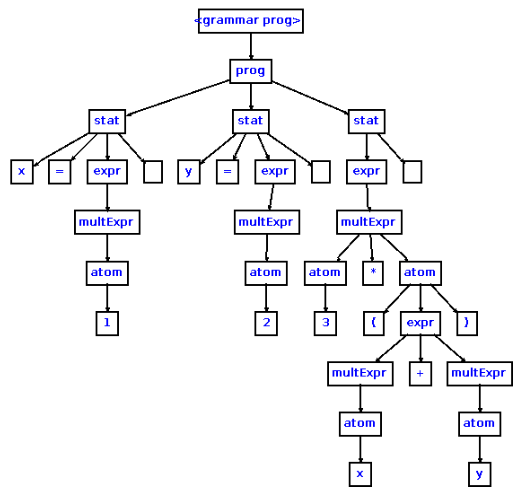
Por ejemplo, para una gramática que acepta expresiones como:
x=1
y=2
3*(x+y)
2
3
este es un ejemplo de árbol sintáctico concreto:
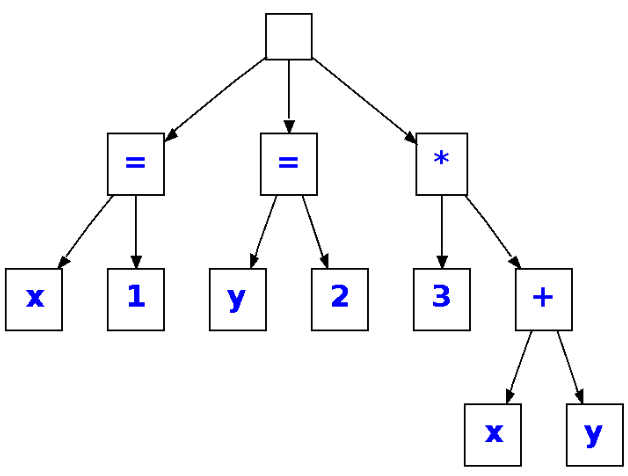
y este un posible árbol sintáctico abstracto con la misma información que el anterior:
# Alfabeto con Aridad o Alfabeto Árbol
No deja de ser curioso que es posible definir un equivalente del cierre de Kleene
Para ello se empieza definiendo lo que es un alfabeto con función de aridad:
# Alfabeto con Función de Aridad
Un alfabeto con función de aridad es un par
denominada función de aridad. Aquí
Denotamos por
# Lenguaje de los Arboles o Términos
Definimos el conjunto de los árboles
- El árbol vacío está en
- Todos los elementos de aridad 0 así como los de aridad variable
están en : implica implica
- Si
y es un elemento -ario o bien es de aridad variable, entonces
Los elementos de
Al igual que cuando parseamos las cadenas hablamos de tokens para hablar de la
ocurrencia en la cadena de un elemento del alfabeto aquí hablamos de nodos para
hablar de la ocurrencia de un elemento
# Aridad de los Nodos en Egg
Los AST con los que trabajamos en nuestro parser son de tres tipos
con aridad:
los nodos VALUE son hojas los nodos WORD los consideramos hojas un APPLY tiene dos hijos: el hijo OPERATOR y el hijo ARGS que es un array los arrays contienen diferentes números de árboles
# Anatomía de los AST para Egg
En cuanto a la implementación, al igual que con los tokens, los nodos son objetos y tienen propiedades.
Todos los nodos tiene una propiedad type que determina que tipo de nodo es y por tanto su aridad.
- Los nodos del tipo
VALUErepresentan constantes (literals) STRINGS o NUMBERS.- Their
valueproperty contains the string or number value that they represent.
- Their
- Nodes of type
WORDare used for identifiers (names).- Such objects have a
nameproperty that holds the identifier’s name as a string.
- Such objects have a
APPLYnodes represent applications. They have anoperatorproperty that refers to the expression that is being applied, and anargsproperty that is an special node:ARRAY
ARRAYis in fact an special node of ASTs that holds the arguments of the application
# Example: AST >(x, 5)
>(x, 5)
>(x, 5)
For example, The AST resulting from parsing the input
>(x, 5)
would be represented like this term:
APPLY(
WORD,
ARRAY[
WORD,
VALUE
]
)
2
3
4
5
6
7
or if we want to explicit the attributes we can extend the notation to look like this:
APPLY(
operator: WORD{name:>},
args: ARRAY[
WORD{name:x}
VALUE{value:5}
]
)
2
3
4
5
6
7
More precisely, describing its actual implementation attributes:
$ cat greater-x-5.egg
>(x,5)
$ ./eggc.js greater-x-5.egg
$ cat greater-x-5.egg.evm
2
3
4
Here is the JSON:
{
"type": "apply",
"operator": {
"type": "word",
"name": ">"
},
"args": [
{
"type": "word",
"name": "x"
},
{
"type": "value",
"value": 5
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
The npm module evm2term (opens new window) allows you to get a compact representation of the AST:
✗ eggc examples/greater-x-5.egg
✗ evm2term examples/greater-x-5.egg.evm
apply(op:word{do}, args:[
apply(op:word{:=}, args:[word{x},value{9}]),
apply(op:word{print}, args:[
apply(op:word{>}, args:[word{x},value{5}])
])
])
2
3
4
5
6
7
8
# Example: AST +(a,*(4,5))
Otro ejemplo, el AST para +(a,*(4,5)) sería
APPLY(
WORD,
ARRAY[
WORD,
APPLY(
WORD,
ARRAY[VALUE, VALUE]
)
]
)
2
3
4
5
6
7
8
9
10
Que explicitando los atributos sería:
APPLY(
operator: WORD{name: +},
args: ARRAY[
WORD{name: a},
APPLY(
name: WORD{name:*},
args: ARRAY[VALUE{value:4}, VALUE{value:5}]
)
]
)
2
3
4
5
6
7
8
9
10
# Gramática Árbol
Una Gramática Árbol en nuestra definición
es una cuadrupla
es un alfabeto con aridad es un conjunto finito de variables sintácticas o no terminales es un conjunto finito de reglas de producción de la forma con y es la variable o símbolo de arranque
NOTA: Regular Tree Grammar (opens new window) en la Wikipedia
# Gramática Informal de los árboles del Parser de Egg
En nuestro intérprete de Egg los árboles usados son los generados por esta gramática:
ast: VALUE
| WORD
| APPLY( WORD ARRAY( ast * ))
2
3
# Notación de Dewey o Coordenadas de un Árbol
La notación de Dewey (opens new window) (1876)
es una forma de
especificar los subárboles de un árbol
La definición formal por inducción sería:
. Esto es, si el sufijo es es el propio árbol Si
y y es una cadena de números y puntos, se define inductivamente el subárbol como el subárbol -ésimo del -ésimo subárbol de . Esto es:
Por ejemplo si:
t =
APPLY(
operator: WORD{name:+},
args: [
WORD{name:a},
APPLY(
operator: WORD{name:*},
args: [VALUE{value:4},VALUE{value:5}]
)
]
)
2
3
4
5
6
7
8
9
10
11
Entonces (indexando en 1), si no me equivoco:
- t/1 sería el árbol WORD{name:+}
- t/2.1 sería el WORD{name:a}
- *t/2.2.2.1 sería VALUE{value:4}
# Es una idea muy repetida: Otras notaciones
En realidad, la notación de Dewey es equivalente al operador "."
que usamos en los lenguajes de programación para denotar los atributos de un objeto.
Con el "." a partir de t podemos construir expresiones como:
t.operator, t.operator.name, t.args.0.name, t.args.1.args.0.value
La misma idea aparece en el uso del operador "/" para denotar subdirectorios en Unix
/src/js/tutu.js y sub-recursos en una URL.
También en el lenguaje XPath (opens new window) para hablar de elementos de los objetos de un documento XML.
For example, the expression "A//B/*[1]" selects the first child ("*[1]"), whatever its name, of every "B" element that itself is a child or other, deeper descendant ("//") of an "A" element that is a child of the current context node (the expression does not begin with a "/").
The language jq (opens new window) to select sub-objects inside a JSON is another example.